- 用逻辑回归、svm和决策树;随机森林和XGBoost进行模型构建,评分方式任意,如准确率等。(不需要考虑模型调参)时间:2天
数据集下载
说明:这份数据集是金融数据(非原始数据,已经处理过了),我们要做的是预测贷款用户是否会逾期。表格中 "status" 是结果标签:0表示未逾期,1表示逾期。
1.数据处理
#这里用根据IV选择出来的特征 features = list(iv_result[iv_result['iv_value']>0.4]['feature']) X = df[features] y = df['status'] from sklearn.model_selection import train_test_split #数据切分 X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.3,random_state=2019) from sklearn.preprocessing import StandardScaler #标准化 scaler = StandardScaler() X_train_scaled = scaler.fit_transform(X_train) X_test_scaled = scaler.fit_transform(X_test)
2.模型导入,模型评估
二分类问题,我用准确率,查准率,召回率,f1指标来评估模型
#导入模型 from sklearn.linear_model import LogisticRegression from sklearn.svm import SVC from sklearn.tree import DecisionTreeClassifier from sklearn.ensemble import RandomForestClassifier from xgboost import XGBClassifier log_clf = LogisticRegression() svc_clf = SVC() tree_clf = DecisionTreeClassifier() forest_clf = RandomForestClassifier() xgb_clf = XGBClassifier() models = {'log_clf':log_clf,'svc_clf':svc_clf,'tree_clf':tree_clf,'forest_clf':forest_clf,'xgb_clf':xgb_clf}
from sklearn.metrics import recall_score,precision_score,f1_score,accuracy_score
def metrics(models,X_train_scaled,X_test_scaled,y_train,y_test): results = pd.DataFrame(columns=['recall_score','precision_score','f1_score','accuracy_score']) for model in models: name = str(model) result = [] model = models[model] model.fit(X_train_scaled,y_train) y_pre = model.predict(X_test_scaled) result.append(recall_score(y_pre,y_test)) result.append(precision_score(y_pre,y_test)) result.append(f1_score(y_pre,y_test)) result.append(accuracy_score(y_pre,y_test)) results.loc[name] = result return results
metrics(models,X_train_scaled,X_test_scaled,y_train,y_test)
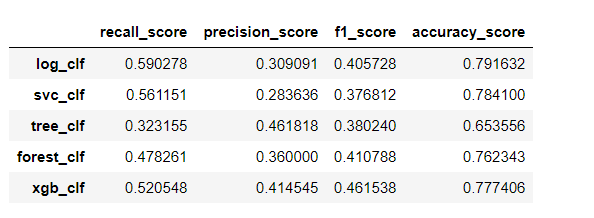 xGBoost效果要好点,但总体看效果不是很好!!
xGBoost效果要好点,但总体看效果不是很好!!



